
Live site:
ml.aiengineer.work
TL;DR: DeepSeek R1 GRPO Benefits
DeepSeek R1 leverages Group Relative Policy Optimization (GRPO) to significantly improve language model reasoning. Unlike traditional reinforcement learning, GRPO simplifies training by:
- Generating a group of outputs for each prompt.
- Scoring each output with a reward function.
- Calculating advantage by comparing individual rewards to the group average.
- Updating the policy to favor better-performing outputs.
This eliminates the need for a critic network, reduces computational demands, and yields models with superior reasoning. Implemented with tools like Unsloth and 4-bit quantization, GRPO can run on consumer hardware (e.g., a single Tesla T4 GPU). Tests on mathematical reasoning show GRPO-trained models exhibit more accurate reasoning paths and results compared to traditional models.
DeepSeek R1
Large language models have advanced significantly, but effective reasoning remains a challenge. DeepSeek R1 addresses this with Group Relative Policy Optimization (GRPO). This article explores DeepSeek R1, its implementation using Unsloth, and the potential of GRPO to enhance LLM reasoning.
Understanding GRPO vs. PPO
Traditional reinforcement learning methods, like Proximal Policy Optimization (PPO), often require complex architectures with separate policy and value models. GRPO simplifies this by eliminating the need for a separate value function, increasing training efficiency and accessibility.
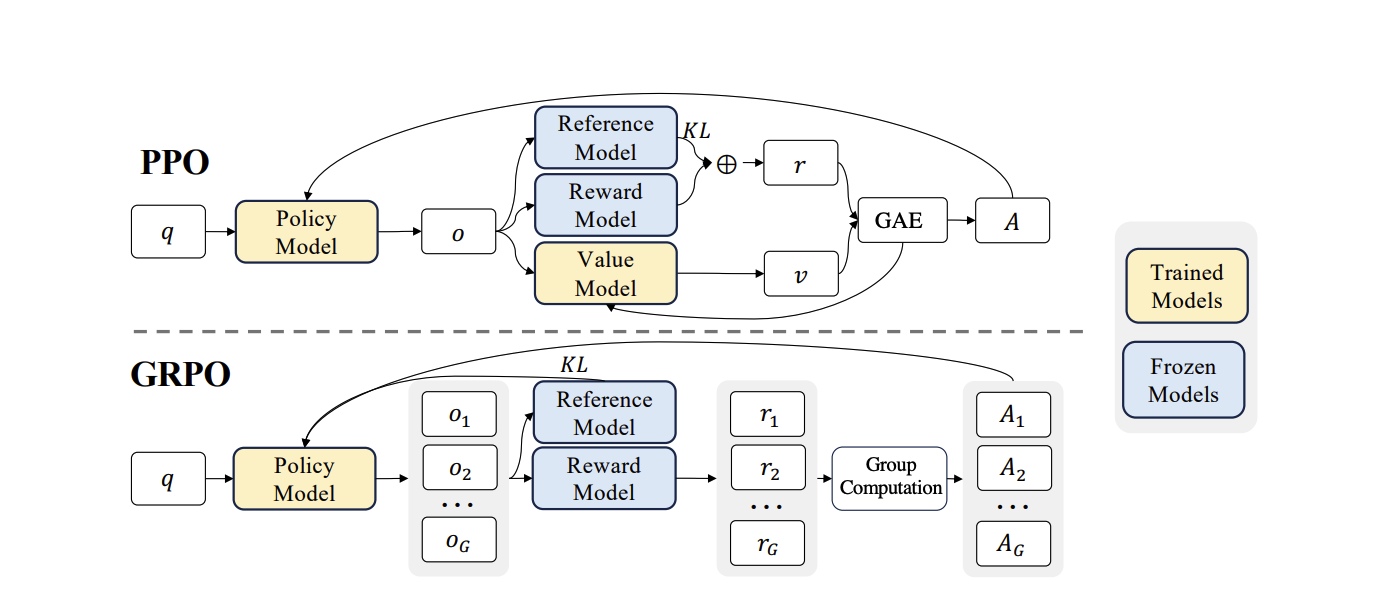
What is GRPO?
GRPO (Group Relative Policy Optimization) is a reinforcement learning algorithm that enhances language model reasoning. Instead of relying on a critic network, GRPO uses a simpler approach:
- Group Sampling: Generates a batch of outputs (a “group”) for each prompt.
- Reward Scoring: Scores each output using a reward function.
- Group-Based Advantage: Calculates each output’s “advantage” by comparing its reward to the group’s average reward.
- Policy Update: Adjusts the policy to promote outputs with positive advantage and discourage those with negative advantage.
This approach is more efficient because:
- It eliminates the need for a separate value function (critic).
- The policy learns relative performance within each sampled group.
- It enables faster convergence with fewer resources.
The DeepSeek R1 Architecture
DeepSeek R1 builds on GRPO to optimize for reasoning tasks. The architecture uses a standard transformer design but focuses training on the comparative quality of reasoning paths.
Implementation with Unsloth
Unsloth facilitates GRPO implementation with modest resources. This notebook used:
- Meta Llama 3.1 8B as the base model.
- A Tesla T4 GPU with 14.74 GB VRAM.
- 4-bit quantization to fit the model in limited memory.
Key implementation details are outlined below.
Technologies Used
The implementation leverages:
- Hardware: Tesla T4 GPU with 14.74 GB VRAM
- Framework: Unsloth 2025.3.19 for fast Llama patching
- Base Libraries:
- Transformers 4.51.1
- vLLM 0.8.3
- Torch 2.6.0+cu124
- CUDA 7.5 with CUDA Toolkit 12.4
- Xformers 0.0.29.post2
- Quantization: BitsAndBytes 4-bit quantization (NF4 format)
- Optimization: Chunked prefill tokens (512) and Num Sequences (160)
This combination allows training a reasoning model on hardware that typically requires significantly more resources.
Data Preparation for GRPO
GRPO’s data preparation differs from supervised fine-tuning (SFT):
- SFT: Directly teaches the model responses using input-output pairs.
- GRPO: Uses input-output pairs to verify answer correctness, providing a reward signal.
I used the GSM8K dataset (grade school math problems), which provides questions and answers. Instead of teaching the model to memorize answers, using answer correctness as a reward signal encouraged better reasoning.
The Training Process
The GRPO training process for DeepSeek R1 involves:
- Initial Sampling: Generating multiple potential solutions for each math problem.
- Reward Calculation: Evaluating each solution for correctness.
- Relative Advantage: Comparing solutions against the group average.
- Policy Update: Adjusting model parameters to favor reasoning paths leading to correct answers.
This helps the model develop better reasoning strategies, not just memorize answers.
Results and Evaluation
The results demonstrate the effectiveness of GRPO. Consider this Python example: calculating π.
def calculate_pi(n):
pi = 0
for i in range(n):
sign = (-1) ** i
pi += (4 / (2 * i + 1)) * sign
return pi
# We need a large number of iterations to get an accurate result
n = 1000000
pi = calculate_pi(n)
print("Approximation of pi:", pi)Pre-GRPO Model
The pre-GRPO model generates a Monte Carlo method for calculating π, which works but is inefficient and unrelated to the prompt’s request to use the Bailey–Borwein–Plouffe formula.
import random
def calculate_pi(num_points):
points_inside_circle = 0
for _ in range(num_points):
x = random.uniform(-1, 1)
y = random.uniform(-1, 1)
if x**2 + y**2 <= 1:
points_inside_circle += 1
return 4 * points_inside_circle / num_points
num_points = 1000000
pi = calculate_pi(num_points)
print("Approximation of pi:", pi)Post-GRPO Model
The GRPO-trained model correctly implemented the Bailey–Borwein–Plouffe formula and calculated π to the expected precision.
def calculate_pi_bbpf(num_digits):
"""
Calculate pi using the Bailey–Borwein–Plouffe formula (BBP formula).
:param num_digits: The number
## 2nd GRPO runs
The value of pi (π) is an irrational number, which means it cannot be expressed exactly as a finite decimal or fraction. However, we can calculate its value to a certain number of decimal places using various mathematical techniques and algorithms.
One way to calculate pi is to use the Gregory-Leibniz series, which is a infinite series that converges to pi:
π/4 = 1 - 1/3 + 1/5 - 1/7 + 1/9 - ...
We can also use the Bailey–Borwein–Plouffe formula (BBP formula), which is a spigot algorithm for computing the nth binary digit of pi:
π = Σ (1/(16^n)) * ((4/(8n + 1)) + (2/(8n + 4)) - (1/(8n + 5)) - (1/(8n + 6)) - (1/(8n + 7)) + (1/(8n + 2)) + (1/(8n + 3)) + (1/(8n + 5)) + (1/(8n + 6)))
Using this formula, we can calculate the value of pi to a certain number of decimal places.
Here's a simplified example using Python code to calculate the value of pi to 10 decimal places:
```python
def calc_pi(n):
pi = 0.0
for i in range(n):
pi += (1/(16**i)) * ((4/(8*i + 1)) + (2/(8*i + 4)) - (1/(8*i + 5)) - (1/(8*i + 6)) - (1/(8*i + 7)) + (1/(8*i + 2)) + (1/(8*i + 3)) + (1/(8*i + 5)) + (1/(8*i + 6)))
return pi
n = 1000 # number of iterations
pi = calc_pi(n)
print("The value of pi is approximately:", round(pi, 10))
The value of pi is approximately: 3.1415926545This demonstrates GRPO’s ability to produce more accurate and relevant reasoning. The model better follows the specified reasoning path.
These improvements were achieved:
- In just a few hours of training.
- Using a free Colab instance.
- With limited computational resources.
Why This Matters
The DeepSeek R1 approach using GRPO is significant because of its:
- Efficiency: Training reasoning models with fewer resources increases accessibility.
- Quality: The resulting models demonstrate improved step-by-step reasoning.
- Applicability: The technique can be applied to various domains requiring logical reasoning.
- Open Source: Tools like Unsloth democratize access to advanced AI techniques.
Practical Applications
Models with enhanced reasoning, like DeepSeek R1, are valuable for:
- Education: Providing step-by-step explanations for complex problems.
- Research: Assisting with mathematical and scientific reasoning.
- Engineering: Helping debug or develop complex systems.
- Business: Improving decision-making with logical analysis.
Limitations and Future Work
Limitations include:
- Reliance on carefully designed reward functions.
- Potential struggles with extremely complex reasoning tasks.
- Dependence on the base model’s capabilities.
Future work could focus on:
- Developing more sophisticated reward mechanisms.
- Combining GRPO with techniques like Chain-of-Thought prompting.
- Scaling to larger models and more diverse reasoning tasks.
Conclusion
DeepSeek R1 and GRPO represent an exciting advancement in teaching language models to reason effectively. The accessibility of this technology, achievable on consumer hardware with open-source tools, is particularly impressive.
The democratization of these techniques paves the way for specialized, reasoning-focused language models that could transform AI interactions across numerous domains.